概述
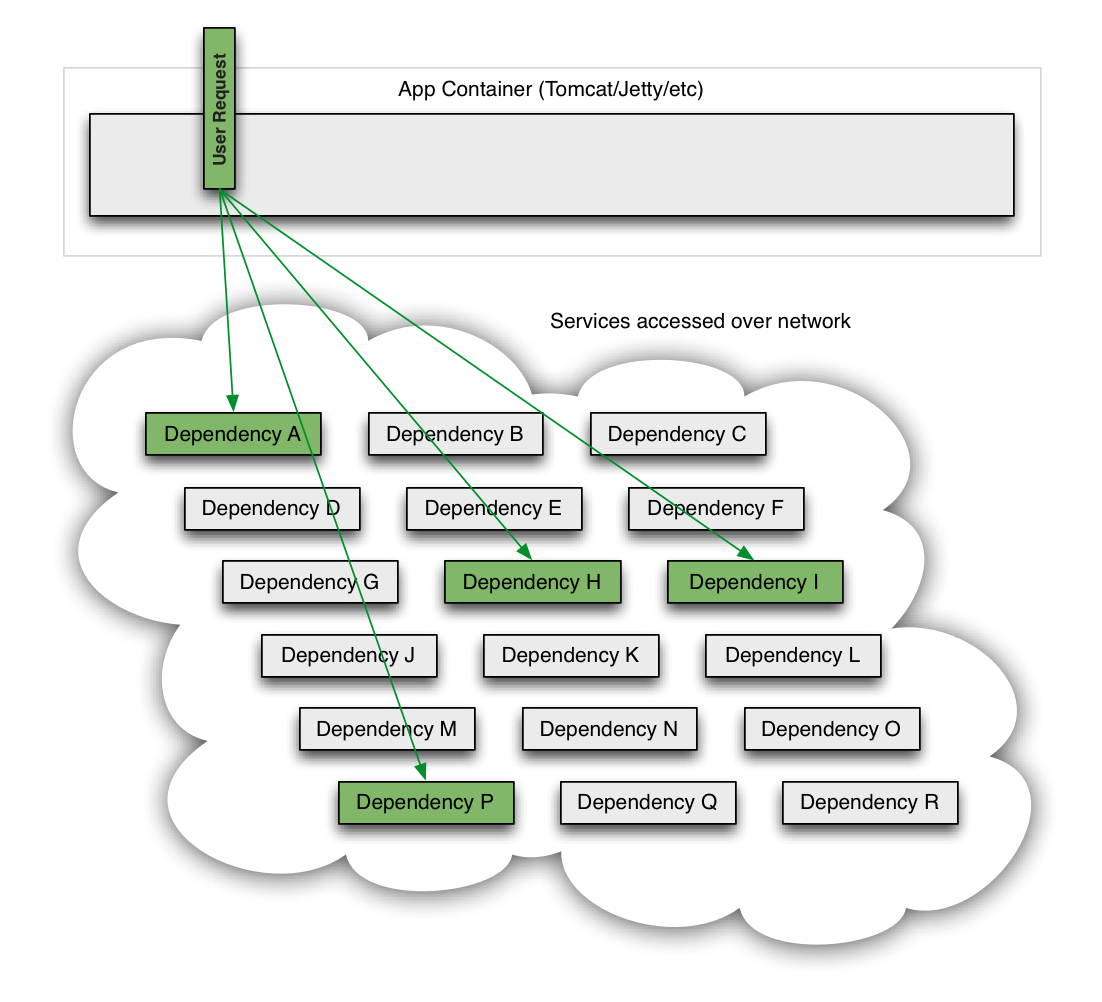
每当调用外部服务或系统时,都可能会发生故障,包括服务器、网络、负载均衡器、软件、操作系统等,没有任何人能构建出永不中断的系统。
超时
造成请求超时的原因有很多,包括网络抖动、限速丢包、业务处理阻塞等。
如果客户端等待一项请求完成的时间比平常更长,它也会因将该资源用于处理请求而将资源保留更长时间。如果大量请求长时间占用资源,服务器的相应资源就可能耗尽。
所以,要对任何远程调用设置超时,包括跨多个进程的任何调用上设置超时(即便这些进程位于相同机器上)。
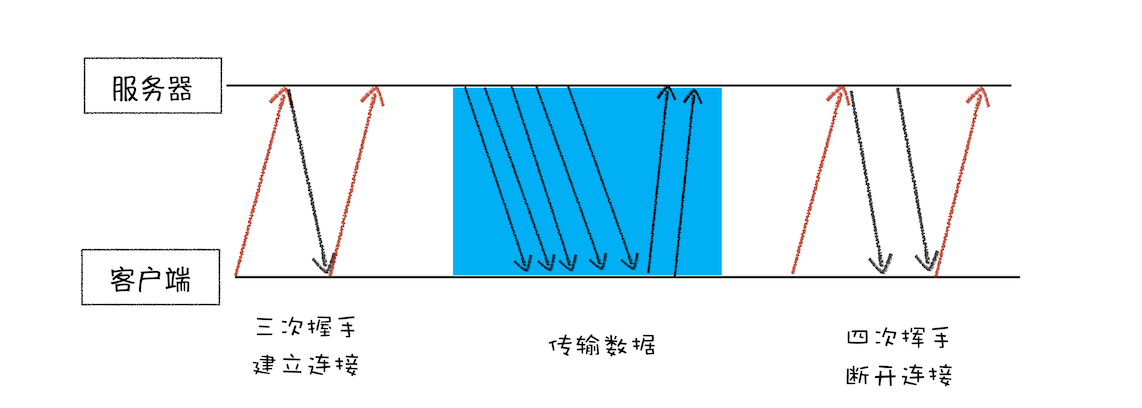
超时包括连接超时和请求超时。
关键点在于超时时间的设置。
超时时间过⻓:容易引起降级失效、系统崩溃、连接池爆满等问题
超时时间过短:容易因⽹络抖动⽽告警频繁,造成服务不稳定等⽤户体验问题
超时设置
- 维度1:⽤户⻆度,根据用户体验,设置在可接受范围内
- 维度2:资源消耗角度,超时时间⻓短应当和QPS成反⽐例
- 维度3:延迟指标角度,可接受的下游服务错误超时率(例如 0.1%),控制延迟百分比范围(例如p99)
重试
有超时问题,就会有重试动作,重试能够获得更大的成功几率,同时,重试也是自私的。
故障通常分为两种,偶然故障或者瞬态故障和服务故障。
对于偶然故障或瞬态故障,重试是很好的解决问题的措施
对于过载引起的服务故障,重试反而会加重问题的严重性,甚至在服务问题得到解决后,由于保持较高的负载造成恢复延迟
重试策略
通常一个复杂的系统内部包含很多层调用,如果每一层都增加重试动作,最终重试次数将翻n倍。
- 单层重试:复杂业务请求,只在某一层做重试动作
- 次数限制:重试次数要有上限,无论何时
- 重试等待:重试之间要有一定的等待时间
- 指数回退:每次等待时间都要呈指数级延长
- 熔断机制:在超过错误阈值时,对下游服务的调用将完全停止
- 速率限制:熔断可能会导致恢复时间延长,可以通过令牌桶的方式,限制对下游服务的重试速率,降低风险
重试约束
- API幂等:API必须要提供幂等性才能保证重试的安全性,只读类API天生幂等,修改类API可以通过令牌等方式实现幂等的效果
- 故障类型:对于客户端错误,重试也基本不会成功,而服务端错误可能在后续尝试中成功
抖动

线性重试问题:假如n个client,均重试1次,最终重试次数呈n的2次方形式增长

sleep = min(cap, base * 2 ** attempt)
指数回退重试:通过每次等待时间指数级增长,最终重试次数将低于n的x次方

指数回退问题:固定回退算法的重试,可能导致重试集中在固定的时间点上

sleep = random_between(0, min(cap, base * 2 ** attempt))
时间抖动:通过增加每次等待时间的随机性,最大可能的分散重试时间点
计划任务
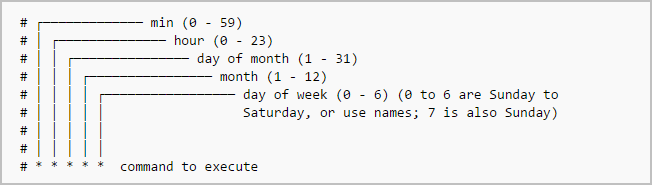
- 问题:周期任务,每次触发时间固定,可能导致流量峰值
- 优化:增加一定的抖动,进行流量削峰;由于流量打乱,可能导致难以快速问题定界
- 措施:同集群内部,不同节点按一定策略增加不同的固定抖动时间
参考
- https://aws.amazon.com/cn/builders-library/timeouts-retries-and-backoff-with-jitter/?did=ba_card&trk=ba_card
- https://network.51cto.com/article/608018.html?edm
- https://www.infoq.cn/article/eyrslar53l6hjm5yjgyx
- https://blog.csdn.net/dfz54668/article/details/102422959
- https://aws.amazon.com/cn/blogs/architecture/exponential-backoff-and-jitter/
- https://www.cnblogs.com/dongl961230/p/14817223.html