概述
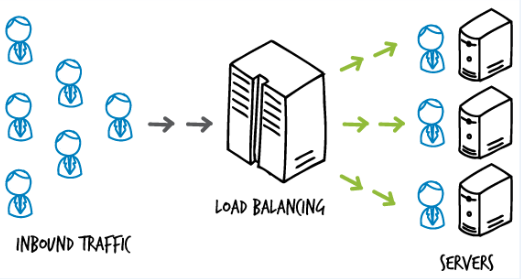
微服务通常的架构:微服务=负载均衡器+服务后端实例*n
服务出现问题时常见场景:
- 网络问题(断链、抖动等)
- 资源问题(CPU、内存、磁盘等)
- 性能问题(请求处理不过来(自身逻辑慢、依赖的服务响应慢等))
下文重点关注性能问题
故障诊断
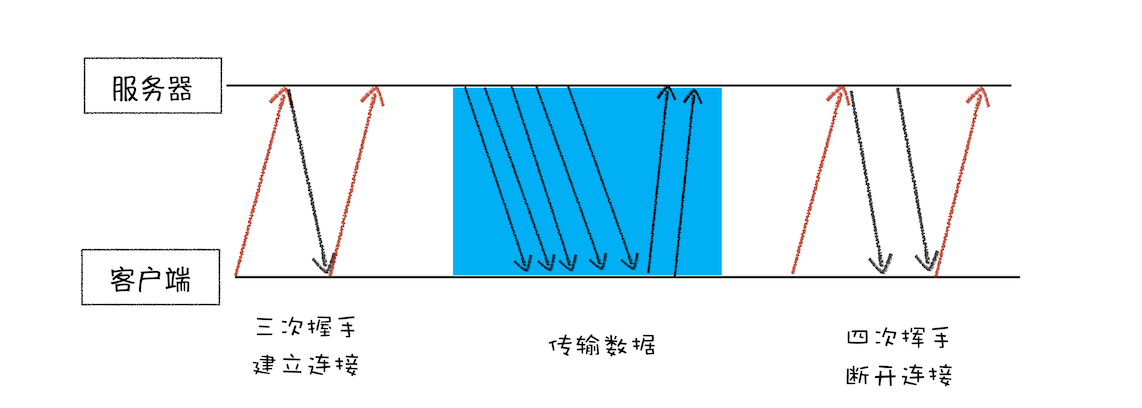
服务请求阶段包括:建立连接、传输数据、断开连接
服务出现问题时的常见阶段:
- 建立连接:无法建立连接,导致无法处理请求
- 断开连接:连接无法释放,导致资源占用,无法处理新的连接
建立连接阶段
分析
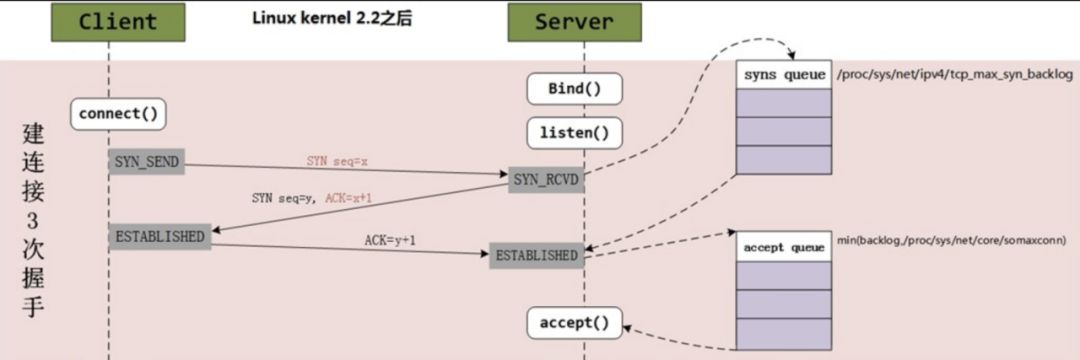
在TCP三次握手的过程中,Linux内核会维护两个队列:
- 半连接队列 (SYN Queue)
- 全连接队列 (Accept Queue)
# -n 不解析服务名称
# -t 只显示 tcp sockets
# -l 显示正在监听(LISTEN)的 sockets
$ ss -lnt
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 [::]:2380 [::]:*
LISTEN 0 128 [::]:80 [::]:*
LISTEN 0 128 [::]:8080 [::]:*
LISTEN 0 128 [::]:8090 [::]:*
通过 ss 命令可以查看到全连接队列的信息:
- Recv-Q:当前全连接队列的大小,即已完成三次握手等待应用程序 accept() 的 TCP 链接
- Send-Q:全连接队列的最大长度,即全连接队列的大小
$ netstat -s | grep -i "listen"
189088 times the listen queue of a socket overflowed
30140232 SYNs to LISTEN sockets dropped
通过 netstat -s 命令可以查看 TCP半连接队列、全连接队列的溢出情况:
- 代表有 189088 次全连接队列溢出
- 代表有 30140232 次半连接队列溢出
如果一段时间内相关数值一直在上升,则表明半连接队列、全连接队列有溢出情况
优化
优化方向主要包括:
- 调整队列大小
- 开启tcp_syncookies
- 开启tcp_abort_on_overflow
调整队列大小
TCP 全连接队列的最大长度由 min(somaxconn, backlog) 控制,其中:
- somaxconn 是 Linux 内核参数,由 /proc/sys/net/core/somaxconn 指定, 默认值为 128
- backlog 是 TCP 协议中 listen 函数的参数
tomcat中backlog=accept-count
# cat /proc/sys/net/core/somaxconn
128
结合服务实际情况,调整参数大小
半连接队列的长度由三个参数指定:
- backlog
- /proc/sys/net/core/somaxconn
- /proc/sys/net/ipv4/tcp_max_syn_backlog 默认值为 1024
具体算法根据内核版本存在不同差异
整体来讲,只要全队列大小配置合理,半队列可以采用默认值
开启tcp_syncookies
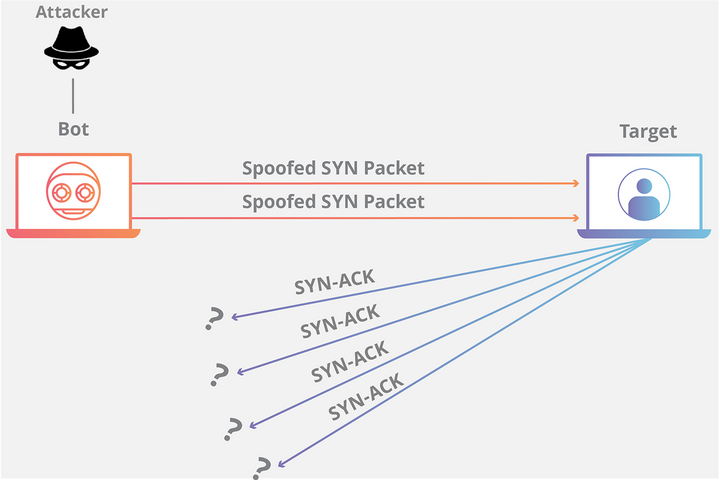
当出现SYN Flood攻击时,半连接队列将会溢出,无法响应合法的SYN请求时,服务将无法正常工作
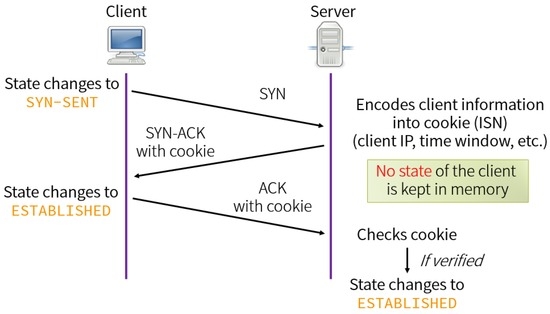
SYN cookie避免半连接队列的溢出,开启 SYN cookie 是一种抵御SYN Flood攻击的简单方式
# cat /proc/sys/net/ipv4/tcp_syncookies
1
开启tcp_abort_on_overflow
全连接队列溢出措施主要包括:
- 丢弃(默认)
- 拒绝
丢弃
Drop ACK包的影响:
- socket 连接仍旧在半连接队列中,等待 Client 端回复 ACK
- Server 端一直在 RETRY 发送 SYN+ACK
最终导致资源占用浪费
拒绝
当队列已经满的情况下,直接拒绝是明智的选择
是否直接拒绝,受tcp_abort_on_overflow参数影响
# cat /proc/sys/net/ipv4/tcp_abort_on_overflow
0
tcp_abort_on_overflow 有两种可选值:
- 0:如果全连接队列满了,Server 端 DROP Client 端回复的 ACK
- 1:如果全连接队列满了,Server 端向 Client 端发送 RST 报文,终止 TCP socket 链接
断开连接

client和server仅代表主动方和被动方,TCP连接的双方都可以扮演Client或Server角色。主动关闭的一方发出 FIN 包,被动关闭的一方响应 ACK 包,此时,被动关闭的一方就进入了 CLOSE_WAIT 状态。
netstat -aonp
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 81 0 0.0.0.0:8080 0.0.0.0:* LISTEN 1/java off (0.00/0/0)
tcp 0 0 127.0.0.1:8100 0.0.0.0:* LISTEN 24/soffice.bin off (0.00/0/0)
tcp 936 0 172.20.4.203:8080 172.20.5.59:40576 CLOSE_WAIT - off (0.00/0/0)
tcp 867 0 172.20.4.203:8080 172.20.4.172:57166 CLOSE_WAIT - off (0.00/0/0)
tcp 964 0 172.20.4.203:8080 172.20.5.59:50106 CLOSE_WAIT - off (0.00/0/0)
tcp 1701 0 172.20.4.203:8080 172.20.4.172:45428 CLOSE_WAIT - off (0.00/0/0)
tcp 1169 0 172.20.4.203:8080 172.20.4.172:61582 CLOSE_WAIT - off (0.00/0/0)
tcp 963 0 172.20.4.203:8080 172.20.4.172:64474 CLOSE_WAIT - off (0.00/0/0)
tcp 1058 0 172.20.4.203:8080 172.20.5.59:44564 CLOSE_WAIT - off (0.00/0/0)
...
统计各状态数量
# netstat -ant | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
CLOSE_WAIT 103
ESTABLISHED 2
LISTEN 6
或
# ss -ant | awk '{++S[$1]} END {for(a in S) print a, S[a]}'
LISTEN 6
ESTAB 2
CLOSE-WAIT 103
通过各个状态的统计数据,判断服务出现问题的可能阶段
通常,CLOSE_WAIT 状态在服务器停留时间很短,如果发现大量的 CLOSE_WAIT 状态,一般有如下几种可能:
- 程序问题:代码不严谨导致没有执行close动作
- 响应太慢或者超时设置过小:一方timeout,另一方还在忙于耗时逻辑,就会导致close被延后
- BACKLOG太大:来不及消费的情况,导致多余的请求还在队列里就被对方关闭了
如果参数配置等没有问题的话,问题大概率集中在,服务无法快速处理请求,导致响应超时的场景
优化
优化方向主要包括:
- 流量进去前:流量控制
- 流量进入后:请求失败
流量控制
常用的流控措施:
- 队列
- 漏桶
- 令牌桶
队列
类似TCP的连接队列,所有请求到来之前统一放入队列,可以按权重分多个队列,服务再从队列中依次处理请求
适应性差。队列过短时,容易触发限流;队列过长时,服务处理不过来
*漏桶
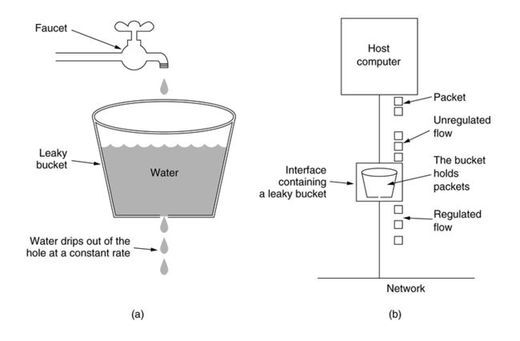
漏桶算法的实现是在队列的基础上加上一个限流器,关键在于使队列的数据能够匀速地消费。
在突发流量的情况下,不能够有效地处理请求,缺乏效率
令牌桶
令牌桶算法的实现是将限流器外置,形成动态速率,在流量小的时候积攒令牌,流量大的时候,可以快速处理
快速适应请求流量洪峰,又能将流量控制再一定的速率下
请求失败
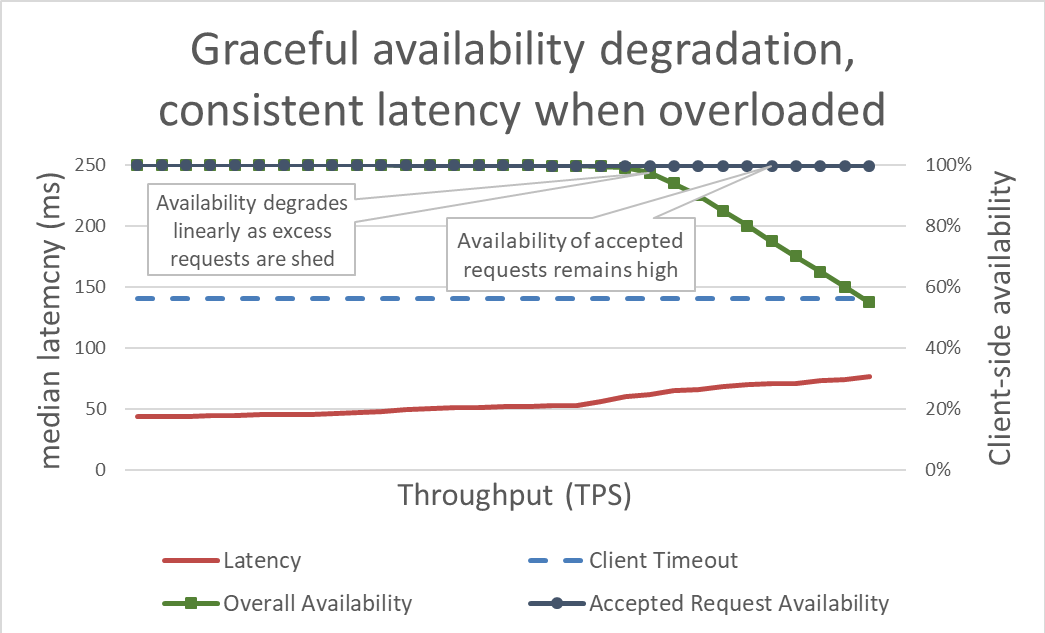
当前流量进入后,确保请求的响应延迟足够低,以便在客户端超时之前作出响应,因为对于客户端认为已经超时的请求,服务端再继续处理就是做无用功,避免浪费的保护措施:
- 客户端在每个请求中包含超时提示,这些提示告诉服务器客户端愿意等待多长时间。
- 服务端可以采用绝对时间(依赖系统全局时钟)或相对剩余时间,决定请求处理的最后期限
- 服务端根据处理耗时预估,判断有必要是否继续当前的工作
参考
- https://aijishu.com/a/1060000000004066
- https://network.51cto.com/article/687595.html
- https://developer.aliyun.com/article/773014
- https://www.dazhuanlan.com/binghushouyeren/topics/1435753
- https://blog.huoding.com/2016/01/19/488
- https://mp.weixin.qq.com/s?__biz=MzI4MjA4ODU0Ng==&mid=402163560&idx=1&sn=5269044286ce1d142cca1b5fed3efab1&3rd=MzA3MDU4NTYzMw==&scene=6#rd
- https://www.cnblogs.com/chopper-poet/p/14618391.html
- https://tech.ebayinc.com/engineering/a-vip-connection-timeout-issue-caused-by-snat-and-tcp-tw-recycle/
- https://aws.amazon.com/cn/builders-library/using-load-shedding-to-avoid-overload/?nc1=h_ls
- https://zhuanlan.zhihu.com/p/29539671
- https://juejin.cn/post/7093729160811511844
- https://xie.infoq.cn/article/eca91dd0bd2455d7b3ea0f3b9
- https://aws.amazon.com/cn/builders-library/using-load-shedding-to-avoid-overload/?nc1=h_ls
- https://www.codetd.com/en/article/13050046