执行顺序

每一步都会在上一步结果的基础上产生一张虚拟临时表
Join
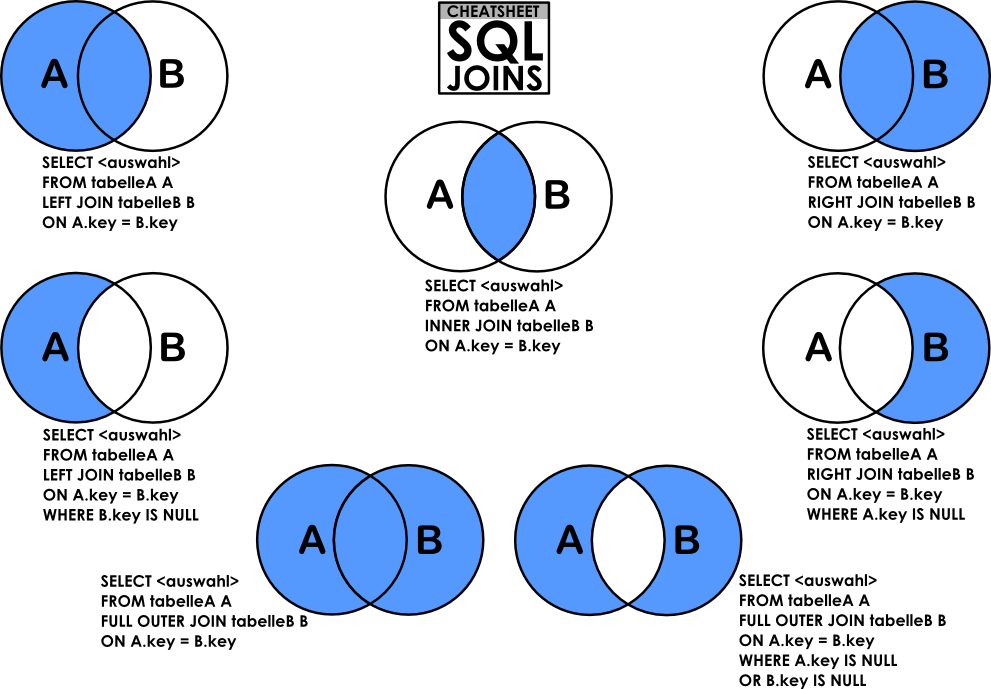
默认为Inner Join
JOIN时条件放在Where和On的区别:
- Inner Join:效果等同
- Other Join:On只决定连接表的字段是否显示,基准表会全部返回不受影响
过程分析
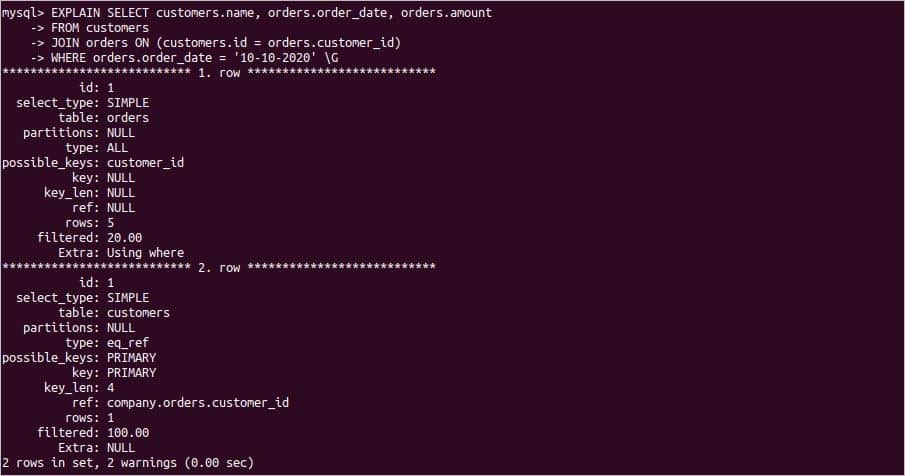
关键列说明:
- id:SQL从大到小的执行;id相同时,执行顺序由上至下
- type:ALL, index, range, ref, eq_ref, const, system, NULL(从左到右,性能从差到好)
- key:索引名,没有选择索引,键是NULL
- rows:估算的找到所需的记录所需要读取的行数
性能优化
- 避免使用
select *,尽量指定具体所需字段。原因:1. 浪费数据库资源;2. 索引覆盖问题,导致数据非必须的二次查询;3. 可维护性差 - 尽量通过
where限制数据范围。 - 尽量通过
limit限制数据数量。 - 在
where中避免使用函数。原因:函数会导致索引失效 - 在
where like中避免使用全模糊匹配%x%,尽量使用左匹配x%。原因:全模糊会导致字符串索引失效 - 避免使用
DISTINCT和ORDER BY,必要时可用GROUP BY替代DISTINCT。原因:慢 - 避免从大规模表衍生小规模表。原因:数据范围需要快速收缩
- 避免使用子查询
IN,尽量使用临时表JOIN。 - 使用索引。
索引

- 最左前缀匹配原则
- 尽量选择区分度高的列作为索引
- 索引列不要参与计算
- 尽量使用联合索引,不要新建索引
参考:
- https://www.cnblogs.com/wyq178/p/11576065.html
- https://www.cnblogs.com/xuanzhi201111/p/4175635.html
- https://blog.csdn.net/ariczhou/article/details/48533287
- https://www.zhihu.com/question/37777220
- https://medium.com/swlh/how-to-optimize-your-sql-query-2a5f0f422887
- https://tech.meituan.com/2014/06/30/mysql-index.html